Řekněme, že stojíte u nového projektu, buď jako fullstack developer nebo jako backenďák programujete nějaké API. Máte naprosto čisté pole působnosti a můžete si to udělat jak chcete.
Že si to můžete udělat jak chcete je ale i nevýhoda. Pokud nemáte dost zkušeností se zvolením špatných architektur, nemáte vůbec tušení, jestli ta, se kterou to zkusíte teď, je ta špatná nebo dobrá.
Každý zkušenější programátor vám řekne, že ať už si zvolíte jakoukoliv architekturu, vždycky se objeví use-case, který vám v této architektuře bude dělat neplechu. A to je také pravda. Ale ještě zkušenější ajťák vám řekne, že zásadní je v kódu nějakým způsobem vyčlěnit doménu a zbytek je jen technologický detail.
Nejdřív bych ale rád pojmenoval ty nejpopulárnější přístupy, podle kterých se IT projekty píšou.
3-vrstvá architektura
V paradigmatu 3-vrstvé architektury se kód odděluje na 3 vrstvy:
- databázová vrstva
- doménová/business vrstva
- frontend/UI vrstva
Databázová vrstva může komunikovat pouze s doménovou a doménová vrstva může komunikovat pouze s frontendovou vrstvou. Snahou tohoto rozdělení je tendence rozdělit kód do oblastí, které spolu co nejvíc souvisí tzn. kód, který souvisí s databází, by měl být v databázové vrstvě, kód který souvisí s doménou by měl být v doménové vrstvě a kód, který souvisí s UI by měl být v UI vrstvě.
Kritika 3-vrstvé architektury: všechno všude, všichni všechno.
Kdekoliv, kde jsem byl, se 3 vrstvá architektura zvrhla v píseček, kde si každý programátor staví svůj vlastní hrádeček.
Jeden programátor do týmu vstoupí, jiný vystoupí, jeden chvíli dělá PR reviewera, ten je posléze taky nahrazen jiným a celá 3-vrstvá architektura se tak časem proměňuje v balast různých optimalizací, wrapperů které wrappují wrappované, business kód v databázové vrstvě, databázový kód v UI vrstvě, UI kód v business vrstvě, SQL procedury na 2000 řádků, nějaký „cool“ mechanismus o kterém už nikdo neví jak funguje, hromady ručně psaných „podpůrných nástrojů“, které je nutné pro normální programování používat a vždy nějaký přesložitělý, komplexní generátor datové vrstvy.
Z jednoduché myšlenky 3-vrstvé architektury, která sděluje, že někdy je nutné oddělovat kód podle typu použití, se stalo dogma, kterému všichni z nějakého důvodu věří ale nikdo jej ani nedodržuje. Je to totiž mylná orientace — není důležitá architektura programátorského projektu ale doména projektu (k tomu co je doména se dostanu). Každá 3-vrstvá nebo n-vrstvá architektura se tak postupně rozpadá jako domeček z karet.
Samoúčelná datová abstrakce, kterou nikdo nepotřebuje
Kdekoliv se používá 3-vrstvá architektura tak tam narazíte na nějaký přesložitělý generátor nebo kód obsahující sofistikovaný labyrint tříd a interfejsů určený pro abstrakci datové vrstvy.
IDataRepository<TDataModel> where TDataModel : IDataEntityCrudDataSource<TDataSourceSelector, TDataModel> : IDataRepository<IDataSourceSelector, TDataModel> where TDataSourceSelector : IDataRepository<TDataModel> …UGH!
Tak už aby někdo řekl pravdu.
Abstrakce datové vrstvy je užitečná hlavně kvůli psaní testů. Jakmile jednou zvolíte v projektu datový zdroj, nikdy se nezmění.
Prostě se to neděje. Fakt. Pokud k tomu vzácně někdy dojde u provozované, produkční aplikace, je to stejně vždy spojené s velikým projektem (proporcionálně k velikosti projektu). Přechod na jiný datový zdroj u běžící aplikace je spojen s miliardou jiných dalších problémů a musí k tomu být opravdu dobrý důvod. Paradoxně v ten moment zjistíte, že ten váš šílený labyrint abstrakcí na tuto situaci není připravený a při přechodu na jiný datový zdroj se vám to rozpadne.
Přestaňte tedy jako programátoři přemýšlet nad tím, co se stane v momentě, kdy přejdete na jiný mechanismus persistence, protože to se v praxi téměř nikdy neděje.
Abstrakce je potřeba kvůli testům. Ale na ty vám stačí jednoduchý interface, který napíšete ručně a nepotřebujete k němu žádný šílený generátor.
Cibulová architektura, n-vrstvá architektura
Toto je všechno variace na 3-vrstvou architekturu. V cibulové architektuře jde o myšlenku, že různé oblasti kódu na sebe navazují postupně a lze si to tudíž představit jako cibuli.
Což…je naprosto neužitečné a neříká to nic o tom, jakým způsobem bychom měli psát kód. Která vrstva je uprostřed cibule? Která na vrchu? Je uprostřed databázová vrstva? Nebo business vrstva? Co když potřebuji sdílet něco napříč všemi vrstvami? („Ne to ne, na to se prej mračil jeden senior, který tu byl přede mnou“) Kam patří unit test business vrstvy? A co unit test databázové vrstvy? A kam patří definice IoC kontejneru?
Stejně jako u 3-vrstvé architektury, problém spočívá v orientaci na architekturu a nikoliv na doménu.
Relační databáze (RDBMS) musí zemřít (většinou)
3-vrstvá/n-vrstvá/cibulová architektura se používá v aplikacích, kde se jako persistence zvolilo SQL. Dlouho totiž SQLko bylo to jediné známé, jak se s daty nejlépe pracuje. V dnešní době ale už existují mnohem smysluplnější alternativy a nové projekty by tak v roce 2022 vůbec nad SQLkem neměly vznikat.
Kde dávají RDBMS smysl
Pracoval jsem pro jednu firmu, kde používali SQL Server a Oracle Server a zpracovávali geografická data. V této firmě zaměstnávali na full-time databázové specialisty, kteří veškerou aplikační logiku programovali v procedurách, triggerech, packages a dalších možnostech databázových systémů …a já jsem se svým trapným C# byl jen podřadný technik, který měl dělat různé aplikační a architektonické vyfikundace a webové servery s UI, které ti databázisti neuměli udělat. Můj trapný ASP.NET Core 2.1 MVC backend nebylo nic jiného, než wrapper okolo databázových procedur.
U takové firmy dává SQL smysl. Databáze je střed všeho, geografické údaje jsou jedním z primárních orientací relačních databází a hlavním zaměstnancem není programátor ale databázový specialista.
Dále dává SQL smysl u malých, osobních projektů, kde je výborný tooling. Např. malý blog, malý eshop a s Entity Frameworkem dokážu být produktivní velmi rychle. WordPress, na kterém běží tento blog, běží nad MySQL. Nahodím to někam na hosting a mám hotovo. MySQL není pro WordPress ideální řešení, je to ale zaběhnuté, známé řešení, existuje k němu perfektní podpora, tooling a související technologie.
Je to docela úchylné. Pokud používám MySQL/SQL Server pro osobní blog, je to jako kdybych si koupil plně vybavené BMW X7 jen abych s tím jezdil na nákup do Kauflandu a z plné výbavy používal jen plyn, brzdu, volant, blinkr a světla. Jasně, základní věci jako tabulky, primární klíč a indexy to umí. Kristova noho, tahle ďábelská mašina ale umí mnohem, mnohem víc, než si zjevně dovedu představit a nic z toho nevyužiju. V IT to samozřejmě nevadí, protože oproti BMW X7, MySQL/SQL Server (Express) mohu používat ihned a zdarma.
Kde nedávají RDBMS smysl
Všude jinde.
Vážně.
Nepoužívejte SQL pokud ho po vás nikdo vyloženě nechce a nemá k tomu dobrý důvod. Používejte pro data pouze dokumentové databáze jako mongodb. Toto píšu na základě svých zkušeností. Kdekoliv, kam jsem přišel k nějakému většímu projektu a používali nějaké RDBMS (většinou SQL Server v mém případě) tak RDBMS byl zdrojem nikdy nekončících problémů.
Důvod č.1 proč přestat používat SQL: prakticky nerealizovatelná horizontální škálovatelnost
RDBMS lze škálovat horizontálně. Prakticky to ale nikdo nedělá, protože to nikdo neumí, protože je to velmi složité. Musí se to analyzovat dopředu někým, kdo tomu rozumí a kdo už nějaké databázové servery škáloval. Programátoři to většinou nechtějí dělat, byť to jsou většinou oni, kdo díky skvělému existujícímu toolingu rozhodl, že se bude používat SQL.
Důvod č.2 proč přestat používat SQL: vysoká cena
SQL se v praxi škáluje jen vertikálně. Pokud stroj nestíhá, pořídí se silnější stroj, což znamená brutálně vysoké náklady za licence a za provoz na příšerně drahých serverech s 50 jádry a stovkami GB paměti.
Důvod č.3 proč přestat používat SQL: náročná optimalizace
Zkušení programátoři ví co jsou B+ stromy, primární/cizí/unikátní klíče, full text indexy, typy constraintů, umíme execution plány, umíme napsat proceduru i trigger byť to děláme strašně neradi…ale u velkých projektů prostě dřív nebo později narazíme na problém, který nedokážeme vyřešit. Máme všechny indexy správně ale prostě to běží z nějakého důvodu pomalu…a nejspíš to souvisí s nějakou procedurou? Ten samý problém se nám začal dít ještě někde jinde. A na podobném místě to začalo dělat deadlocky. A to jsem myslel, že když sem dám READ COMMITED tak to vyřeším…
Většinou pak my programátoři pácháme na SQL různé zločiny, dokud to nezačne fungovat, protože databáze nepovažujeme za svoji hlavní specializaci a nebaví nás se RDBMS takhle dlouho věnovat. Tyto zločiny vedou k menší stabilitě a udržitelnosti projektu a většinou se nám později vymstí někde jinde a kolotoč se opakuje. Ve velkých projektech, kde se používá RDBMS, programátoři spoustu času neřeší nic jiného, než problémy spojené s databázemi.
Důvod č.4 proč přestat používat SQL: nevyhnutelné deadlocky
Každý rostoucí projekt, který začne používat RDBMS, narazí na ochrnující problémy s deadlocky. Nevyhnutelně, zaručeně, bez absolutně žádné závislosti na profesionalitě vývojářů.
Typy transakcí v RDBMS nejsou sice tak složité na pochopení ale jak projekt roste, přestává být udržitelné sledovat, která transakce ovlivňuje kterou, jaké tabulky, řádky se uzamykají, jaké musí být čteny, kdy jsou v pořádku „dirty reads“ apod. V praxi to nikdo nesleduje, nikdo to neanalyzuje a nehlídá – programátoři volí SQL v dobré víře, že to znají, dokážou v tom být rychle produktivní a zbytek se nějak zvládne. Ale jakmile v určité velikosti projektu začne SQL vystrkovat růžky, už se tím nechtějí zabývat a projekt trpí kritickými bugy s deadlocky a špatnou optimalizací souběžností.
Důvod č.5 proč nepoužívat SQL: delegování souběžnosti
To, že programátoři zápasí s deadlocky a optimalizací není ten hlavní problém.
Většina programátorů se k SQL vztahuje tak, jako kdyby jim ACIDita a transakce všechny problémy se souběžnostmi vyřešili a oni se tak mohou soustředit na své úžasné nabobtnalé CRUD frameworky a generátory databázových vrstev. Tady mám tabulku s uživateli, tady tabulku s produkty, tady tabulku se skladovými zásobami — super, všechno narvu do transakce a SQL se za mě postará o zbytek!
Hlavní problém je v tom, že programátor vůbec delegoval souběžnosti na databázi, což je přístup, který mu projde u malého/interního projektu. Souběžnosti má mít programátor plně pod kontrolou ve svém kódu, protože stanovení souběžností je součástí domény —- jinými slovy, to, jaké procesy mohou běžet paralelně a jaké ne je zájmem zadavatele, i když to zadavatel třeba neumí přesně analyzovat a zadat.
Zadavatelé většinou nedokážou souběžnosti identifikovat, musí vám být ale schopni říct, co je racing-condition a co ne, když se jich zeptáte. Příklad: pokud ve stejném čase vznikají dvě obědnávky nad zbožím, u kterého zbývá poslední kus, zadavatel musí říct: ano, zde platí kdo dřív příjde, ten dřív mele. Super! V takovém případě dokážete přesně říct, nad kterými entitami/hodnotami umístit zámek či semafor.
Ze začátku můžete nahrubo uzamykat celé entity a v případě potřeby můžete vždy optimalizovat uzamykání nad konkrétními hodnotami. A budete vždy rychlejší, než jakékoliv SQL. Pokud má být projekt připravený na horizontální škálovatelnost tak musíte používat distribuované zámky, ale to není těžký problém (zámky umí dobře obstarávat Redis).
Důvod č.6 pro nepoužívat SQL: delegování domény (business vrstvy)
Pokud se rozhodnete, že přestanete používat transakce, své RDBMS omezíte jen na čtení a na čistě atomické DML (insert, update, delete) a souběžnosti si pohlídáte sami tak jediné, co ještě můžete užitečně používat, je referenční integrita dat skrz primární a cizí klíče, procedury a triggery a jiné vyfikundace databázového systému.
Přestaňte používat procedury, triggery a jiné vyfikundace databázového systému. Tento článek je psaný pro programátory a ne pro databázové specialisty, kteří se psaní procedur, triggerů, viewů apod. věnují full-time. Programátor píše business vrstvu správně v kódu a ne v databázi. Projekt je tak mnohem přehlednější a jasnější.
Primární klíče, cizí klíče, unikátní klíče, constraints atd. jsou delegování business vrstvy do datové vrstvy! Referenční integrita je sice strašně cool ale to, že uživatel a objednávka je ve vztahu 1:N by mělo být patrné z kódu, nikoliv z databáze. Jakékoliv „unikátní klíče“ jsou pak jen rozmělňováním business znalostí z domény do databáze.
Jakmile všechny tyto věci vyhodíte a začnete používat SQL čistě jako mechanismus persistence tak vám dojde, že používáte BMW M7 k ježdení do Kauflandu a začnete hledat jiná NoSQL řešení.
(RDBMS je adekvátním systémem pro čtení např. u systému pro datovou analýzu, datamining, data warehousing atd. či jako uložiště pro readmodely (o readmodelech níže))
Aspektově orientované programování (AOP)
Za celou svoji profesní kariéru jsem se nikde s tímto přístupem nepotkal byť si myslím, že je to celkem cool přístup a rád bych viděl nějaký větší, primárně v AOP psaný projekt. V C# tento způsob rozhodně není moc populární – jediný známý AOP projekt je komerční PostSharp.
AOP je paradigma, které rozlišuje různé „aspekty“ které se k IT projektu vztahují napříč mnoha úrovněmi: logování, databázi, autorizaci, autentizaci, business logiku atd. apod. a každý tento „aspekt“ se programuje odděleně „navěšením se“ na existující infrastrukturu.
Dle mého se ale tento přístup v C# nepoužívá hlavně proto, protože tu samou funkcionalitu „navěšení se na něco“ splňují dekorátory (decorator pattern). Když jsem si s PostSharpem naposledy hrál, projekt se celkem dramaticky zpomalil a běžel jak želva.
Pročítal jsem si ještě https://www.postsharp.net včetně dokumentace a včetně stránky s ksichtem Scott Hanselmana, což je v .NET komunitě velké jméno z Microsoftu a nepřesvědčilo mě o výhodách tohoto komerčního projektu, který ale v nějaké edici mohu použít zdarma, absolutně nic.
Aktoři (Actor)
Actor model je velice cool model, ve kterém je váš kód tlačen do aktorů. Zjednodušeně řečeno: aktor je instance třídy, která má vlastní identifikátor a s daným identifikátorem může v rámci této třídy běžet pouze jedna metoda a ostatní volání čekají ve frontě (tzn. obyčejný semafor, ten je však implicitní).
V .NET světě existují tři projekty, které využívají aktory:
- MS Orleans
- akka.net
- dapr (potažmo Service Fabric Reliable Actors, programuje se to stejně)
Výhody: skvělé pro online hry
Dva hráči hrají nějakou online hru a každý z těchto hráčů je reprezentován aktorem. Tito hráči reprezentují s objekty, které se v této hře nachází — tyto objekty jsou také reprezentovány aktory.
Aktoři jsou ideální pro use-case, pro který byly vytvořeny: pro virtuální interakce v online hrách. Každý aktor reprezentuje objekt, se kterým lze dělat právě jen jedna akce a ostatní akce čekají ve frontě, ze které mohou být vyhozeny/přerušeny či posunuty výše. Aktoři mohou vytvářet nové aktory a volat existující aktory — což přesně pasuje do modelu virtuálního světa, kde se hýbe mnoho věcí najednou a operace aktorů a interakce mezi aktory jsou definované.
Nevýhody: A pak někoho napadlo s aktorama naprogramovat API pro eshop…
Muselo k tomu nevyhnutelně dojít. Já sám jsem byl součástí projektu, kde se aktoři přes DAPR používali k programování API do mobilní aplikace pro koncové uživatele. Sám jsem byl z aktorů celkem nadšený, když jsem se o nich naučil, než jsem dospěl k názoru, že aktoři jsou skvělí jen pro online hry či virtuální online světy a pro psaní backendů se naprosto nehodí.
Nefunguje to. Nepoužívejte prosím vás aktory pro obyčejné systémy jako jsou eshopy, API (neherních, formulářových) mobilních aplikací a podobně. Aktoři jsou fakt velmi specifická architektura, která dává smysl u online her nebo něčeho podobného.
Doménu, ve které se nachází objekty jako User nebo Product nedává smysl reprezentovat skrz aktory. Jasně: působí to dost dobře a „doménově“ když definuji, že u každého uživatele či produktu lze zavolat jen jednu metodu. Dává nám to pocit, že jsme zvítězili nad problémem souběžností (concurrency) a zbavili jsme se deadlocků a v kontextu konkrétního aktora jsme si vždy jisti, že běžíme v jednom vlákně.
Jenže…potom z aktorů využíváme prakticky jen mechanismus lockování a navíc máme toto lockování striktně limitované na jedinou metodu v aktorovi. Což by neměl být až zas takový problém, musíme si ale dávat pozor na to, abychom v aktorovi nekombinovali dlouho běžící proces s často volanou metodou. To je ale zbytečné omezení, na začátku projektu nikdy nemáme informace o konkrétním použití.
Jak se má programovat proces, ve kterém potřebujeme aktivovat dva aktory různých typů najednou? Jeden nápad je skrz jiný typ „kompozitního“ aktora, jehož identita se skládá z identit všech aktorů, se kterými pracuje. Na první pohled celkem hezký nápad. Jak ale „kompozitní aktor“ interaguje s ostatními „kompozitními aktory“? Mělo by to být vůbec možné? Jak ohlídáme, že nějaký programátor nenapíše nějakého long-running metodu do kompozitního aktora, který se ale musí spouštět často? Jak by se měly třídy kompozitních aktorů pojmenovávat: UserProductCompositeActor? Co když mám operaci, kde potřebuji interagovat s 5 dalšími aktory? Kompozitní aktoři přináší víc otázek než odpovědí a víc rizik než jistot.
Místo kompozitních aktorů tak můžeme používat nějaké obyčejné služby…ale jaký je pak rozdíl mezi aktory a službami s nějakým obyčejným uzamykáním skrz semafor? K čemu je dobré používat relativně komplexní architekturu, když z této architektury používáme jen tu nejtriviálnější část? A co se vlastně v aktorech samotných píše: Volají se služby? Nebo obsahují rovnou business logiku a píšou data do repozitářů?
Měly by se přes aktory číst data? To rozhodně ne: u většiny businessů je 90% operací čtení a 10% zápis (o tom píšu ještě níže) oproti online hrám, kde aktoři napřímo ovládají svá data a poměr operací pro čtení a zápis je mnohem vyváženější (např. každý pohyb hráče v prostoru je zápis dat ve změně souřadnic). V aktorovi konkrétní instance může běžet vždy jen jedna metoda najednou což by u eshopu velmi rychle vedlo k timeoutům a nejspíš i k deadlockům.
Měly by tedy existovat aktory u objektu jako je Product zvlášť pro zápis a zvlášť pro čtení? Ale …to pak není nic jiného, než CQRS (o kterém píšu níže). Navíc oproti aktorům CQRS readmodel nemá problém s tím, že je čten z více vláken na jednou což je u většiny businessů žádoucí.
Doménové programování
DDD neboli Domain Driven Development je programátorské paradigma, ve kterém se soustředítě na doménu. Doménou zde není myšlena doména jako např. „domena.cz“ ale nejlépe bych to nazval jako oblast pravidel businessu.
Co myslím pravidly businessu? To jsou instrukce, kterou my programátoři dostáváme od svých nadřízených, od projekťáků nebo od zadavatelů. Příklad:
- „Po kliknutí na tlačítko se musí odeslat objednávka a poslat email na dispečink.“
- „Pokud uživatel aplikuje víc jak jeden slevový kupón, vezme se ten s nejvyšší slevou“
Většina programátorů ve své profesi neurčuje znalosti businessu. My programátoři jen převádíme tyto znalosti do kódu a snažíme se, aby ten software fungoval přesně tak, jak si to zadavatelé přejí.
Programování domény vychází z myšlenky, že je velmi užitečné psát kód, který vyjadřuje znalosti businessu napřímo.
Příklad: PHP blog vs. C# API
Použiju příklad se slevovými kupóny z předchozího paragrafu – pokud uživatel aplikuje víc jak jeden slevový kupón, vezme se ten s nejvyšší slevou.
Jak to na programuje začátečník v PHP? (Jakým jsem byl já v roce 2005) Třeba následovně.
V souboru create_order.php je kus kódu, který přečte $_POST['discount_coupons'] pole IDček slevových kupónů. Přes MySQL si všechny slevové kupóny načtu a přes max(array_column($data, 'discount_percent')) (nebo bůhví jak…) si zjistim výši slevy.
Celý kód by mohl vypadat tedy asi nějak takto:
//create_order.php
if(isset($_POST['discount_coupons'])) {
$statement = $sqlConnection->prepare("SELECT * FROM coupons WHERE id IN (?)")
$statement->bindParam($_POST['discount_coupons']);
$couponsSql = $statement->execute();
$maxDiscount = max(array_column($couponsSql, 'discount_percent'));
//...hotovo
}
A na tomto způsobu programování není absolutně nic špatného. Funguje to, napíše se to rychle, práce je hotova. Když jste začátečník, kterého zaměstnávají na dělání relativně malých projektů, webů a eshopů se sexuálními pomůckami jako mě v roce 2005 tak tento způsob psaní kódu naprosto stačí.
Podle paradigmatu doménového programování bych dnes v C# totéž zadání napsal takto:
private readonly ICouponRepository repository;
public async Task PlaceNewOrderAsync(NewOrder newOrder)
{
var couponIds = newOrder.Coupons.Select(c => c.ID)
var repoCoupons = await repository.FindCouponsAsync(couponIds);
int maxDiscount = repoCoupons.Max(c => c.DiscountPercent);
//atd...
}
Kromě zjevného rozdílu v odlišném zápisu dvou úplně odlišných programovacích jazyků, jaký je rozdíl z pohledu programování podle doménového paradigmatu?
PHP: Musíte PHPko aspoň trochu znát, abyste věděli, že isset($_POST) kontroluje, že přišel HTTP POST request, že $_POST obsahuje asociativní pole, že SELECT * FROM coupons je SQL dotaz nad nějakou relační databází, že bindParam je nastavení parametru do SQL dotazu protože spojování řetězců je SQL injection….doménová znalost je ztracena uprostřed obrovského množství technologických závislostí. Ten, kdo čte ten kód, musí znát PHPko, HTTP protokol a relační databáze protože jedině s těmito znalostmi pochopí, že kód jenom vybere tu nejvyšší slevu ze všech kupónů.
C#: V C# kódu je vyjádřeno:
- že zde máme nějaký kupónový repozitář, kde jsou kupóny uloženy v ICouponRepository. Schválně to je psáno takto, protože v této části kódu nás nezajímá, jak je repozitář implementován.
- že zde máme nějakou operaci PlaceNewOrderAsync která zjevně znamená, že vytváříme novou objednávku
- že z nové objednávky vybereme přes Select(c => c.ID) IDčka kupónů a podle nich vyhledáme kupóny v databázi přes FindCouponsAsync
- že ze všech kupónů v databázi zjišťujeme maximální slevu
(poznámka: Zápis v C# lze napsat stejně i v PHP — „doménově“ lze napsat kód i v PHP. V C# lze napsat kód tak, že přečteme data z HTTP POSTu a z relační databáze.)
Ten rozdíl, který chci zvýraznit je v tom, že v prvním zápisu je hromada technologických závislostí — musíte znát HTTP protokol a relační databáze, abyste věděli, co ten kód dělá.
V druhém zápisu je ale míra abstrakce taková, že nám stačí jen trochu znát C# a hned ze zápisu vidíme, co se děje. Není zde HTTP protokol, není zde relační databáze ale jen klasická manipulace s informacemi, ve které se snažíme co nejpřesněji vyjádřit to, co po nás chtěl zadavatel. To je podstata doménového programování.
Když programujeme doménu, soustředíme se na:
- jasnou sémantiku kódu — jinými slovy text, který kód vyjadřuje, odpovídá významu toho, co ten kód dělá.
- kód, který reprezentuje myšlenky a přání vlastníka businessu což pro nás programátory je většinou náš klient, zaměstnavatel, nadřízený, manažer, projekťák, analytik, architekt, atd. (nebo my samotní)
DDD – agregáty
V DDD se pod pojmem „agregát“ (aggregate) schovává něco, čemu by klasický programátor z 3-vrstvé architektury řekl „business objekt“.
Agregát je hlavní logická jednotka s identitou, na kterou je doména dělena. Každý agregát s identitou je zcela nezávislý na zbytku domény tzn. pokud děláme něco s agregátem „Produktu“ tak nesmíme dělat vůbec nic s agregátem „Skladu“. Typy agregátů jsou od sebe izolované tak moc, že je možné si je představit jako zcela oddělené služby, které fungují na samostatných serverech a nevědí o sobě navzájem.
Sága je název pro speciální služby, do kterých vstupují příkazy, které provádí operace nad více agregáty najednou, různých i stejných typů. V rámci ságy zpravidla kontrolujeme unikátnost emailů nebo distribuujeme operace na jednotlivé agregáty v rámci operace „Vytvoření objednávky“.
CQRS – oddělení čtení a zápisu
CQRS neboli Command Query Responsibility Segragation je paradigma, které říká, že 80% operací je čtení a 20% je zápis, u některých projektů kterými jsme prošel bych řekl klidně až 95% a 5%.
S CQRS souvisí koncept read modelů což je název pro ručně tvořené pohledy, které vás zajímají, přesně optimalizované pro čtení, které potřebujete. Diskový prostor je podstatně levnější, než procesorový čas takže ve tvorbě svých readmodelů se můžete nafukovat.
Myslím si, že je velmi důležité v kódu architekturně oddělovat čtení a zápis právě kvůli CQRS. Pokud máte malý projekt nad relační databází tak v C# používáte Entity Framework na čtení a na zápis a je vám CQRS naprosto lhostejný – oddělovat čtení a zápis nedává smysl.
Pro větší projekty či projektu, u kterých plánujete růst se ale vyplatí CQRS aplikovat:
Spousta zátěže na serverech je ze čtení. Pokud potřebujete serveru ulevit, vytvoříte read model s vlastní indexací atd. atp. a nemusíte se bát, že to zasáhne cokoliv jiného. Nafukujte se na desítky i stovky gigabajtů nenormalizovaných dat, protože diskový prostor je levný. CQRS nutí programátory přemýšlet nad doménou jako nad pravidly, které se věnují zápisu. Ostatní data se dají rekonstruovat buď naživo (silná konzistence, např. SQL View) nebo dodatečně (eventuální konzistence, např. asynchronní read model). CQRS a eventuální konzistence CQRS je odbočením od doménového paradigmatu. Zadavatelé totiž téměř nikdy nerozlišují mezi čtením a zápisem. Zadání „Tady se musí vypisovat X“ je pro zadavatele v úplně stejné důležitosti, jako „Po kliknutí na tlačítko se musí stát Y“. Oddělování kódu dle CQRS je ale dle mého oběť, která se vyplatí.
CQRS je obrovská výhoda pro každý rostoucí projekt, že se vyplatí jej implementovat, nebo se na něj minimálně připravit už na začátku projektu. Na začátku může být všechno čtení a zápis ze stejných databází. Z pohledu CQRS máme data v silné konzistenci tzn. to, co vidíme v UI je to, co je aktuálně (nebo téměř aktuálně) platné, protože je to napřímo přečtené z databáze.
Jak ale projekt začne růst a databáze se začne zavařovat, přejdeme na asynchronní read modely (které vůbec nemusí být ve stejné databázi, ani na stejném serveru), které na základě událostí vyhozených z domény rekonstruují pohled, který potřebujeme.
Toto znamená, že máme data v eventuální konzistenci tzn. to, co vidíme v UI, nemusí být aktuálně platné, ale víme, že po dokončení asynchronní aktualizace nad readmodelem to platné bude. Pro 99% use-case toto není problém. Samozřejmě když říkám „není problém“ tak tím nemám na mysli to, že trvá hodiny a hodiny, než se váš read model zaktualizuje. Většinou existuje vysoká tolerance pro aktuálnost zobrazované (tzn. z readmodelu, nikoliv pravdivá z domény) informace např. o aktuálním stavu zboží, ta může být u většiny businessů až v minutách ale zpravidla by neměla trvat déle, než pár vteřin.
Není to problém také proto, že náš projekt v první řadě nikdy v silné konzistenci nebyl. Většina programátorů, zvyklá z SQL, přistupuje ke čtení dat jako k něčemu, k čemu lze přistupovat paralelně a při čtení nedochází k uzamčení čtených dat ani, pro čtení ani pro zápis. Paranoidní konzistence znamená, že dokud klient neobdrží data, která chce číst, nikdo jiný k těm datům nemá přístup ani pro čtení, ani pro zápis, což je ale use-case užitečný tak možná v nějakém těžce security prostředí, než v obyčejném eshopu/CMS.
Když přijdete za svým zadavatelem a řeknete něco na způsob „Můžu vyřešit to, že náš web bude rychlejší ale znamená to, že se může nějakým uživatelům někdy zobrazit to, že zboží je skladem, i když není. Objednat zboží, které není reálně skladem, stále nepůjde, jenom to potrvá to pár vteřin, než se aktualizuje informace, že zboží skladem už není.“ tak většina zadavatelů řekne, že to není absolutně žádný problém. Pokud nemáte nadřízené nějaké negramoty tak každý projekťák rozumí trojúhelníku čas-kvalita-peníze ve kterém si vždy můžete vybrat dvě věci na úkor jedné.
Asynchronní readmodel je drobné snížení kvality – přecházíme ze silné konzistence na eventuální – rychle a za málo peněz (pokud jsme s CQRS počítali už na začátku). Snížení kvality přechodem ze silné na eventuální konzistenci je ale naprosto přemláceno zvýšením responsivity SQL serveru, který není zahlcený SQL dotazy. Díky tomu dokáže zpracovat víc objednávek (například).
Architektura á la Miroslav Bartl
Tak je na čase ukázat, jak píšu doménu já. Stejně jako tento článek, je to prostě jen můj subjektivní názor založený na mých zkušenostech a na tom, jak to vyhovuje mně a co považuji za užitečné jak při tvoření solo projektů tak i při práci v týmu.
Agregát jako logická jednotka, nikoliv jako konkrétní třída
V první řadě je nutné identifikovat agregáty. Neprogramuji své agregáty jako třídy ale spíš jako oblasti, které obsahují kód, který se k danému agregátu vztahuje. V C# projektu si takto pojmenuji celou složku jako User nebo jako Product což jsou mé agregáty. Agregát je kořen stromu tzn. mé agregáty mohou obsahovat jiné objekty, kolekce objektů atd. apod.
V rámci těchto agregátů uplatňuji stejné pravidlo, jako v DDD: jednotlivé agregáty, ať už různých nebo stejných typů, na sebe nevidí. Tzn. jakýkoliv proces, který běží v kontextu agregátu, nevidí na žádný jiný agregát. (Jak řeším kolektivní business pravidla popíšu níže).
Ságy se většinou vztahují přímo k danému agregátu – potom je umisťuji do složky „Sagas“ k danému agregátu. Proč?
V rámci agregátu chci řešit pouze izolovanou logiku agregátu a přímý kontakt s repozitářem, který patří pouze danému agregátu. V operacích, které běží přímo nad agregátem, neřeším zámky/semafory, ty řeším v dané sáze.
Někdy nelze ságu ke konkrétnímu agregátu přiřadit. Jsou to zpravidla operace, které se zabývají mnoha různými agregáty najednou, jako například „Vytvoření objednávky“. Tyto operace dávám do složky „_Sagas“ s podtržítkem na začátku pouze pro účely řazení.
Model agregátu jako anemický model
Dle DDD definice je agregát jedna třída, která obsahuje všechny vlastnosti a metody, které se k agregátu vztahují. Jak jsem popsal výše, toto spíše vede k problémům.
Dle mého názoru třída agregátu má pouze svoji reprezentaci. Tomu se říká anemický model, který je některými lidmi tak strašně moc nesnášen.
public record User
{
public string Id { get; init; }
public string Name { get; init; }
//... atd
}
A teď bacha.
- Reprezentace agregátu je modelem dokumentové databáze. Tzn. reprezentace agregátu je to, co je uloženo v NoSQL. Není žádné rozlišení mezi „business“ a „repo“ objektem, repozitář pracuje se stejným typem, jako handler.
- Reprezentace agregátu může vstoupit do UI a může přicházet z UI ale není to podmínka. UI téměř vždy potřebuje nějaké své vlastní modely, za překlad mezi UI modelem a doménovým modelem je odpovědné UI.
Pokud se kroutíte odporem, tak je to dobře. Znamená to, že konfrontuji vaše zaběhlé, dogmatické představy o tom, co je udržitelný kód.
Ad. 1 + 2) Agregát je sdílený model. DB/UI modely se tvoří podle potřeby.
Koukněte se na to takto: repozitář je součástí domény. Doména zahrnuje business kód + interakce čtení/zápisu s repozitářem. Není důvod vytvářet různé modely pro business a pro repozitář, protože obojí je součástí domény.
Repozitář je abstrahovaný jako interface, to sice ano, ale hlavně kvůli testům, abych nemusel v testech složitě mockovat všechny ty typy, které náleží do MongoDB.Driver NuGetu. Nemám důvod předpokládat, že budu přecházet na jiný způsob persistence a stejně tak byste neměli ani vy!
Mapování mezi C# třídou a MongoDB BSON dokumentem je triviální a vytváření dalších modelů nepřináší vůbec žádnou další výhodu.
Jako programátoři bychom se měli snažit psát vždy co nejméně kódu a každý kód, který píšeme, by měl být dobře čitelný sám o sobě, aniž by potřeboval komentář.
V MongoDB stačí Collection<T>.InsertOneAsync(T model) a máme hotovo.
Používat stejný model v DB a v UI není žádný zločin. Stačí se na to nekoukat jako na DB/business model ale jako na doménový model. UI modely se ale mohou rozlišovat a velmi často rozlišují a proto psát zvlášť UI modely a mapovat mezi UI a doménovými modely je v pořádku — ale pouze tam, kde se UI od domény opravdu liší a ne kategoricky všude, to je úplně k ničemu.
Pokud je UI model totožný s doménovým modelem, pak děláte věci správně, programujete doménově! Vaše UI je totožné s tím, jak jsou data uložená v databázi a jak jsou reprezentována v paměti. Nemáte vůbec s ničím moc práce a to, co se po vás chtělo, je v kódu zapsáno správně nejen správně sémanticky, ale i graficky.
Pokud nastane situace, kdy v důsledku autorizace různí uživatelé musí vidět různá data nebo kdy nad existující strukturou agregátů lze vytvořit zjednodušující pohledy tak to nevadí. Prostě vytvořite UI model/endpointy s takovou strukturou, jakou potřebujete a proveďte potřebnou transformaci v obou směrech. Práce, kterou trávíte psaním takového kódu, odpovídá tomu, co je pro projekt potřeba udělat.
Pokud je UI oddělené od nějakého API tak se na API nedělají UI modely ale RequestModely – filozofie je ale stejná. Pokud UI skrz API pracuje s naprosto identickým modelem, proč bychom měli v API posílat něco jiného?
Jakmile máte zadání, vaše architektura by měla být taková, že většinu času strávíte čas psaním produktivního kódu a ne psaním architektury.
MediatR
V rámci agregátů používám populární a známý MediatR. Je to v jádru velmi jednoduchý projekt, který nedělá nic světoborného ale to co dělá, dělá správně.
V rámci agregátu má každá operace svůj vlastní request a pro každý request existuje jeho request handler, ve kterém je tato operace zpracovávána. IRequestHandler je interface, takže jedna třída může obsahovat kód pro zpracování více requestů.
Na obrázku výše mám dva handlery: LocationHandler a LocationPictureHandler které zpracovávají všechny requesty tohoto agregátu. Toto rozdělení je čistě orientační.
Místo handlerů jsem mohl psát klasické služby a fungovalo by to úplně stejně, není v tom absolutně žádný rozdíl. MediatR používám, protože:
- sjednocení mechanismu pro vyvolávání událostí – kromě toho, že MediatR umí příjmat requesty a zpracovávat je v request handlerech (1:1) tak umí přijímat notifikace a v notification-handlerech (1:N). Notifikace využiji pro vyvolávání událostí, nad kterými mohu psát read modely.
- služby reprezentující metody agregátu v jedné třídě jsou gigantické a partial class zápisu se snažím vyhnout, pokud nejde o generovaný kód. Request může být v RequestHandleru který zpracovává víc requestů, nebo v odděleném handleru, který zpracovává jen ten daný request.
- requesty, které vstupují do handlerů, jsou obyčejné třídy které lze hezky mapovat na online endpointy. Pokud se online endpoint musí odlišovat, pak související mapping probíhá v daném endpoint projektu (MVC, gRPC…).
Nevýhodou tohoto zápisu je, že musíte psát zvlášť request pro ságy a v ságách musíte psát requesty pro konkrétní agregáty.
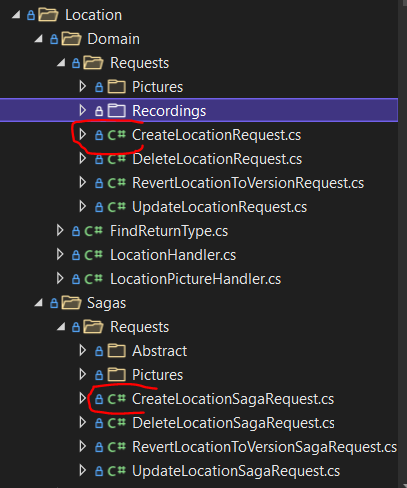
Na obrázku výše jsou dva zvýrazněné requesty:
CreateLocationSagaRequestCreateLocationRequest
Používám konvenci, že pokud se request/request handler týká ságy, má suffix SagaRequest nebo SagaRequestHandler zatímco u agregátů je suffix pouze Request nebo RequestHandler.
CreateLocationSagaRequest vstupuje do handleru ságy. V kontextu ságy ještě nejsem v konkrétním agregátu, mám zde ale dovoleno vytvářet zámky, číst z jiných agregátů a dělat si vlastně úplně cokoliv napříč celou doménou — nesmím ale provádět přímý zápis do žádného repozitáře, to mohu dělat pouze skrz RequestHandlery konkrétních agregátů.
Na příkladu výše před vytvořením objektu Location v doméně je nutné přečíst nějakou konfiguraci a provést různé validace na základě hodnot z jiných agregátů. To je možné udělat pouze v sáze. V rámci agregátu Location dochází už pouze k lokálním validacím. RequestHandler agregátu má přístup ke svému repozitáři ale už k ničemu jinému.
Validace
Poslední, o čem chci v tomto článku mluvit, jsou validace.
Pokud píšeme API, se kterým komunikuje jeden frontend, který je odpovědný za to, že před odesláním validuje data, tak je dle mého naprosto v pořádku používat klasické vyhazování Exceptions. Každá zalogovaná a vyhozená exceptiona je totiž indikátorem chyby buď na backendu nebo na frontendu. V každém případě jde o výjmečný stav, který někdo musí fixnout.
Pokud jsme v API na které se napojuje prakticky kdokoliv a každý si ho volá jakkoliv chce a nemůžeme se od frontendu spolehnout absolutně vůbec na nic (nebo jsme ve strašidelném prostředí, ve kterém je API zodpovědné za správné validační hlášky, které pak frontend pouze zobrazuje) tak je nutné myslet na to, že vyhazování Exception je značný performance-hit a vyhazování validačních chyb je lepší napsat nějak jinak.
V MediatRu lze každou IResponse obalit do nějaké DomainResponse nebo ValidatedResponse která obsahuje výsledek dané operace. Je však dle mého důležité snažit se držet validace co nejblíž v operacích které potřebují validace vykonávat. Nějaký „validátor“ by se mělo vyplatit psát až pouze tehdy, pokud máme opravdu v kódu více než jedno místo, kde jedna a tatáž validace musí proběhnout.
Validace je část kódu, jež reprezentuje doménu a proto bychom se zvlášť u validací měli soustředit na to, že kód je sémanticky co nejjasnější a že význam psaného kódu pokud možno přímo vyjadřuje myšlenky zadavatele/businessu.